Architecture
The architecture is a robust ingestion pipeline combined with scrapers and clients that collect information about software components.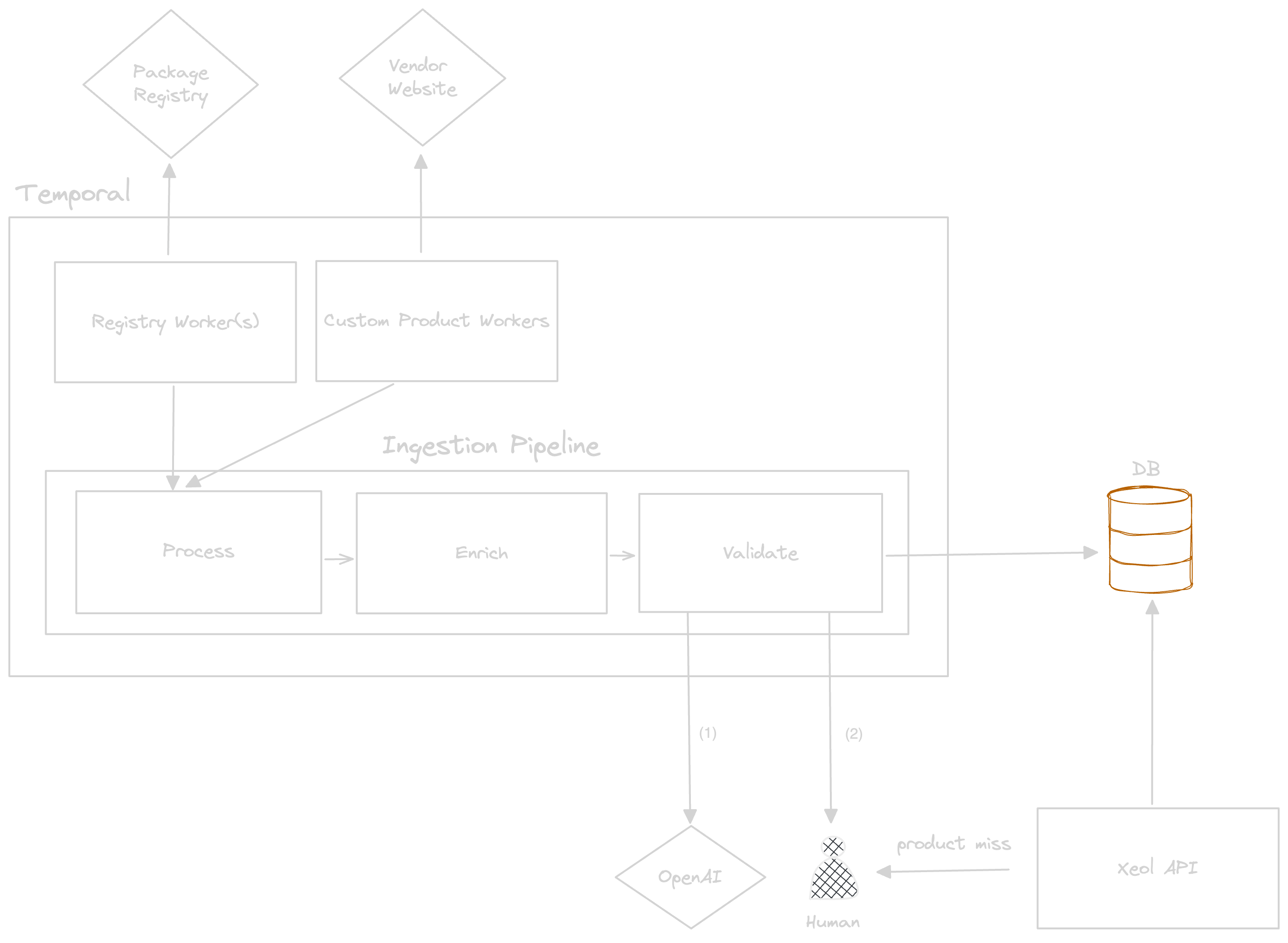
Workers
The workers are responsible for collecting information. They run weekly on a cron schedule to fetch information about known software components.Registry Workers
The registry workers are responsible for collecting information from package registries. These workers will fetch the top 10,000 most depended packages for each registry and fetch information about the state of their deprecation status for each version.Custom Product Workers
The custom product workers are resopnsible for collecting information about custom products that do not exist in a registry such as Wireshark, Windows, Adobe products, OperatingSystems, and other commercial or commercial OSS software.Ingestion Pipeline
The ingestion pipeline is responsible for processing the data from the workers and storing it in the database. The pipeline is responsible for ensuring that the data is consistent and accurate. There are three main components to the ingestion pipeline:Process
During this stage, the data is processed and transformed into a consistent format.Enrich
During this stage, the data is enriched with additional information such as EOL dates if not already present, and other metadata about the software such as the archival status of the source repository. This stage also includes generating EOL dates for products based on the encoded vendor support policy. For example, Firefox has a vendor support policy such that when a new minor version is released, the previous minor version becomes EOL.Validate
In order to ensure that the component data is highly consistent and accurate, we validate the data to be stored in two ways. The first pass includes using GPT-4 to validate the data and metada about the component. If the data is flagged as incorrect, a human will intervene to diagnose the problem and fix the data. The second pass includes manual review of the data by a human to ensure that EOL dates and other metadata about the component is accurate.Xeol API
The Xeol API is responsible for serving the data to clients. The API serves component information in a consistent format. In the case of a client request that results in a miss (no component was found), the API will report this information to a human to investigate. In the case of there being no component in our database, the component will be added to the queue to be tracked. And in the case that a component exists, but we lack coverage of identifier information (CPE or PURL), identifiers will be updated on the component. Since PURLs and other naming information is generated in a decentralized manner, we can not reliably generate PURLs for all components beforehand. This feedback loop ensures that as time goes on, we will have more and more coverage of component identifiers. If you’d like to read more about the “naming problem” in software identification, you can read more on Tom Alrich’s blog here or a report by CISA called Software Identification Ecosystem Option AnalysisEOL Software Tracked
We can track EOL for 2 main types of software, open source packages and commercial software. OSS ComponentsNuGetnpmMavenPyPIGolangRubyGems
- Operating Systems (Linux, Windows, macOS, RHEL, etc)
- Databases (MongoDB, MySQL, PostgreSQL, etc)
- Web Servers (Apache, Nginx, etc)
- Application Servers (Tomcat, JBoss, etc)
- Middleware (RabbitMQ, Kafka, etc)
- Runtimes (JDK, .NET, etc)
- Browsers (Chrome, Firefox, etc)
- Desktop Client Software (Office, Adobe, etc)
Definition of EOL
Vendor Announced
The vendor has a support policy for this software and has announced an EOL date. This usually only applies to Commercial and Commercial OSS.
Registry Deprecated
The package maintainer has marked an entire package or specific package versions as deprecated on the package registry.
Repository Archived
The source repository for the package has been archived and is no longer maintained.
Data Coverage and Consistency
Here’s how we’re thinking about the coverage and accuracy of the data in our EOL database: Accuracy For each software component, we gather all releases for that software by scraping release data from the official vendor webiste, source repository, or package registry. We check our database to ensure the version is tracked in some way. We have a two pass validation process for each component. The first pass is done by GPT-4 and the second pass is done by a human. This ensures that the data is highly accurate. Coverage When requests hit our API, we track which requests have been “misses” (no component found). In the case of there being no component in our database, the component will be added to the queue to be tracked. And in the case that a component exists, but we lack coverage of identifier information (CPE or PURL), identifiers will be updated on the component. This feedback loop ensures that as time goes on, we will have more and more coverage of components and component identifier information. Resiliency The entire ingestion pipeline and all workers are running in temporal workflows. Each Temporal workflow is able to maintain its state and progress even in the face of failures, crashes, or server outages. This allows us to build resilient pipelines that can reliably handle the scraping of data from potentially unreliable websites. Each worker runs on a cron schedule. In the case that the vendor website has changed significantly and we are no longer able to parse it, the scraper will error out and trigger an alert to our team which will then investigate and remediate manually.FAQ
How do I get an API key to play with your EOL database?
How do I get an API key to play with your EOL database?
Message us at
founders@xeol.io with your name and company and we will get you an API key to start playing!What identifiers do you support to match software?
What identifiers do you support to match software?
We support matching software on
purl , cpe , or name + versionWhat about EOL data for software that is not listed above?
What about EOL data for software that is not listed above?
We are always expanding the coverage for our EOL database. Message us at
founders@xeol.io and we will add the software you want within a week.How often is the EOL data refreshed?
How often is the EOL data refreshed?
Weekly
Do I have to parse the different EOL, deprecated, or archived dates myself?
Do I have to parse the different EOL, deprecated, or archived dates myself?
No, our API will return a boolean eol field and a datetime eol_date field for each product. We broke it down into different categories (EOL/EOS vs extended support vs deprecated vs archived) to highlight the differences in how commercial software and open source packages treat or signal end-of-life.